記憶圖
記憶圖(Memory Graph)解決長跑 RP 裡最常見的一個痛點:角色失憶。
LLM 的上下文視窗是有限的。聊到幾百輪以後,早期的重要資訊——人物關係、關鍵事件、世界規則——會被截斷丟掉。角色就「忘了」之前發生的事。記憶圖把對話裡的關鍵資訊自動抽成結構化的知識節點,需要時再召回注入回 prompt——讓角色能像你一樣,記住 500 輪前發生的事情。
它不是簡單的關鍵詞搜尋或純向量檢索。記憶圖用圖結構和多層演算法,讓召回既語意相關又覆蓋全面——不會出現「只把最相似的五條拉出來,其他都丟了」的情況。
它怎麼工作
記憶圖後台跑三件事:自動提取、智慧召回、分層壓縮。
自動提取
每次 AI 回覆後,記憶圖分析對話內容,把值得記住的東西提取出來,產出結構化的知識節點。提取可以走兩條通道:
內建提取 —— 當記憶面板裡的 自動抽取 開關打開時,記憶圖在每次 AI 回覆後自己跑一次 LLM 呼叫,把 schema 裡的結構化欄位填出來。這是預設方式,不依賴任何其他擴展。
編排器驅動的提取 —— 當編排器擴展已安裝,且導演模式使用預設配置時,主 agent 在每次起草回覆後會調度一個 memory_curator 子 agent。memory_curator 跑多輪「觀察—執行」迴圈,先用記憶圖的唯讀工具確認現狀,再寫入。對像角色這類穩定事實節點,品質通常更高 —— agent 會先查是否已有同名角色,而不是直接新建出重複節點。
兩條通道可以同時開,它們彼此並不協調,等於用額外的 LLM 成本換取一層兜底。多數使用者只會留一條。
只走編排器驅動的提取:
- 打開記憶面板,把 自動抽取 關掉。
- 在編排器配置編輯器裡確認
memory_curator已啟用,並且由主 agent 調度(新裝預設就是這樣)。
節點分兩層。預設 schema 自帶下面這三種類型,但 schema 是完全可定制的。你可以新增節點類型(奇幻題材加 magic_system,政治題材加 faction,生存題材加 inventory_item,看你的卡需要什麼),也可以移除任何預設類型。下面欄位也是預設值,每種類型的欄位可以在 Schema 編輯器裡改(下面會講到)。
語意層節點(持久化結構化知識,合併和更新):
| 類型 | 說明 | 例子 |
|---|---|---|
character_sheet | 角色的姓名、身份、性格、目標、隨身物品 | 「Eileen 是治癒師,認下了對主角的一份恩情」 |
location_state | 地點的名稱、控制者、危險度、資源 | 「黑暗森林由精靈控制,危險度高」 |
事件層節點(情節記錄,每次提取新建,從不合併):
| 類型 | 說明 | 例子 |
|---|---|---|
event | 發生過的重要事件 | 「主角在森林中遭遇伏擊」 |
事件節點不一樣
事件節點和其他類型有本質區別:
- 每次提取都新建節點。 標題自動遞增。事件是時間軸上獨立的點,不像角色狀態那樣合併到現有節點
- 最高層時間線總是注入。 事件節點是核心劇情上下文——最高層級的總結永遠在 prompt 裡,確保 AI 始終把握劇情走向
- 被壓縮的低層事件隱藏。 事件累積太多時,舊事件向上壓縮成更高層的總結。低層事件依然在圖裡,需要時召回機制能再發現它們,但預設不持久注入
簡單說:AI 始終能看到「大事」(最高層總結),具體細節只在對話需要時召回補充。
可以透過 提取間隔 控制提取頻率——比如設為 2 表示每 2 次 AI 回覆才觸發一次提取,LLM 呼叫成本減半。
智慧召回
你發新訊息觸發 AI 生成時,記憶圖根據當前對話上下文,從累積的記憶中召回最相關的節點,注入 prompt 供 AI 參考。
| 召回方式 | 說明 |
|---|---|
| LLM 召回 | 讓 LLM 直接從記憶庫裡挑相關節點,支援多輪深度探索 |
| RAG 召回 | 對嵌入的記憶庫做向量檢索,可選疊加交叉編碼重排和 LLM 查詢改寫 |
選哪個?
LLM 召回是預設的,因為最容易配 —— 你的主對話已經有 LLM API,這就夠用了。
RAG 召回更快、更貼近生產級檢索系統的玩法(語意向量檢索)。需要先設好嵌入檔案(embedding profile):檔案放在 Connection Manager 的嵌入面板裡,和聊天補全連線並列,多個外掛(Vector Storage、記憶圖、未來的擴充)可以共用同一份 provider/模型/key 三元組。
RAG 召回裡有兩個獨立的開關,可以用額外成本換更好的效果:
- 啟用重排 —— 在向量命中之上加一道交叉編碼重排。當嵌入模型偏小、重排模型偏強時收益最明顯;需要設定一份重排檔案(cohere / jina / 自訂端點)。
- 啟用查詢改寫 —— 在檢索前加一次 LLM 呼叫,把最近幾輪對話改寫成一句更適合向量檢索的簡潔句子。當使用者的提問比較泛、或者繞彎子時,召回品質提升明顯。代價是每輪多一次 LLM 呼叫(延遲+成本)。
經驗法則:剛上手就 LLM 召回;碰到成本或延遲瓶頸、或者想讓召回結果在換模型後保持穩定時,切到 RAG 召回。兩個開關相互獨立,可以分別打開試用。
分層壓縮
隨著對話推進,事件記憶持續累積。記憶圖自動對老事件做向上壓縮——多個相關事件合併為更高層的總結節點,既保留核心資訊又控制總記憶體積。
壓縮是遞迴的。某層的總結節點也超閾值時,繼續向上壓縮,直到節點數降到閾值以下。例如多個戰鬥事件先壓成「森林戰役」,多場戰役再壓成「北征之戰」。壓縮後的總結節點仍可展開看原始子事件。
和提取類似,壓縮也有兩條通道:
內建壓縮 —— 當記憶面板裡的 自動壓縮 開關打開時,葉子層事件累積到閾值後,記憶圖跑一次性的 LLM 總結呼叫。
編排器驅動的壓縮 —— memory_curator 在提取之後會評估 memory_compaction_candidates,然後用 KEEP/FOLD/DROP 風格的總結呼叫 memory_compact_nodes。多輪 agent 可以一個 rollup 一個 rollup 反覆迭代,而內建路徑是一次性的。
它實際長什麼樣
讀到這兒大多數讀者都想知道一個具體問題:節點到底長什麼樣?來個真實例子。
假設你和 Eileen(一個治癒師 NPC)有這樣三輪對話:
You: 我把找到的傷藥遞給 Eileen。
Eileen: ...謝謝。但你確定要給我?這種東西在外面很值錢。
You: 你傷得比我重。再說,我們是朋友吧。
Eileen: ...嗯。是朋友。這個恩情我會記著的。
這一輪後,記憶圖在後台跑一次提取,產生這樣的結構化節點:
{
"id": "n_eileen",
"type": "character_sheet",
"level": "semantic",
"title": "Eileen",
"fields": {
"aliases": "",
"traits": "話不多,字斟句酌,即使道謝也很克制",
"identity": "在北境遇到的旅行治癒師",
"goal": "還這份恩情;傷好到能自己走路",
"inventory": "傷藥(剛收下)、輕便行囊",
"language_sample": "...謝謝。但你確定要給我?",
"addressing_user": "稱呼用名字,中間常有停頓"
},
"floor": 12
}{
"id": "evt_20260505_001",
"type": "event",
"level": "semantic",
"title": "Summary 1",
"fields": {
"summary": "時間: 第 12 天傍晚\n地點: 北境驛道旁的臨時營地\n\n使用者把背包裡僅剩的傷藥遞給受傷的 Eileen, Eileen 短暫遲疑後接下, 並以平穩的語氣明確認下了這份恩情和二人之間的朋友關係。\n\n不可逆:\n- 使用者與 Eileen 建立朋友關係\n- Eileen 欠使用者一份明確承認的恩情"
},
"floor": 12
}這就是預設 schema 的欄位
上面例子裡的欄位(character_sheet 用的 aliases / traits / identity / goal / inventory / language_sample / addressing_user,event 用的 summary)就是預設表的真實列。Schema 編輯器裡可以改名、刪除,或者乾脆加新類型。
記憶圖的面板裡你能看到所有節點,可以是圖,也可以是表格:
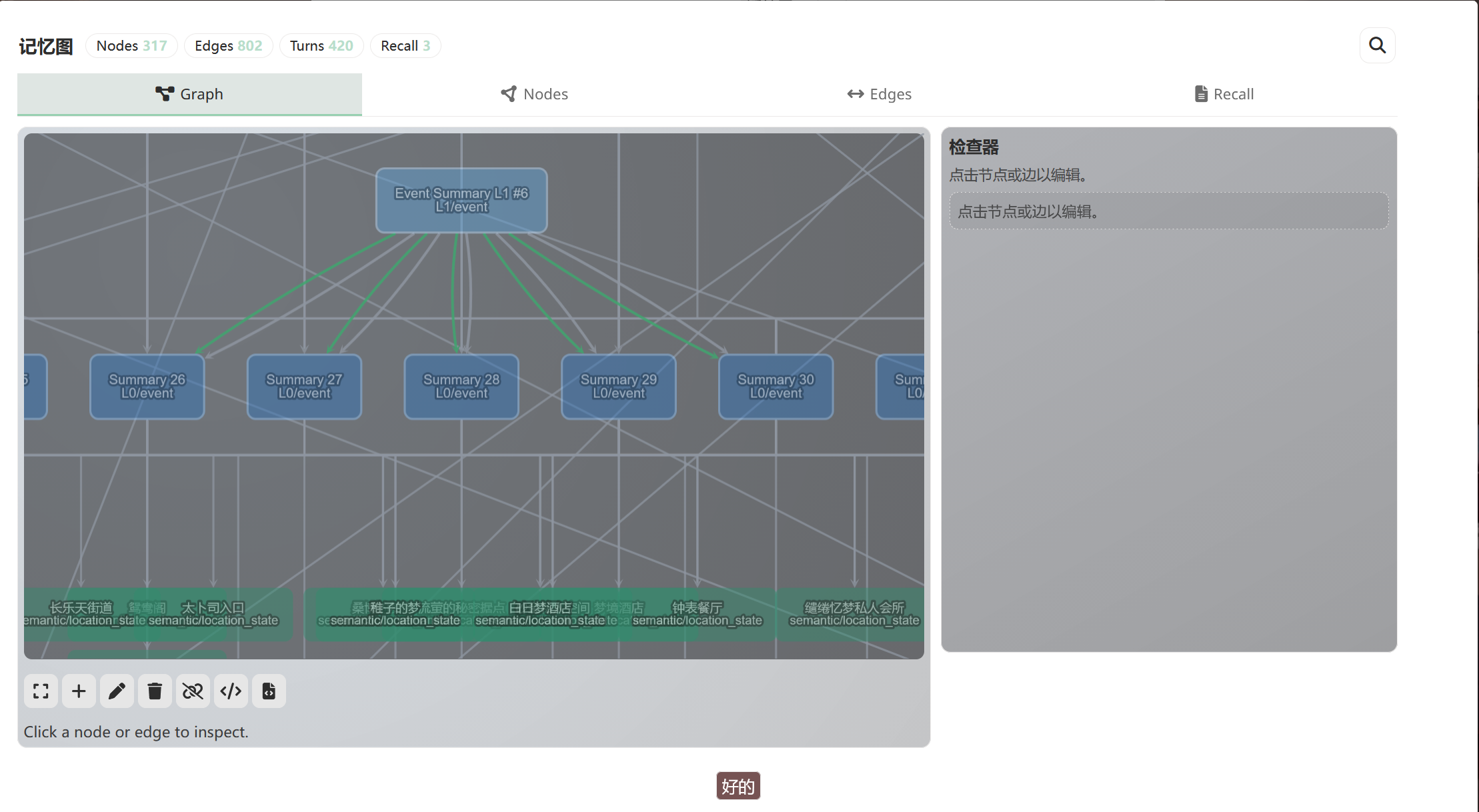
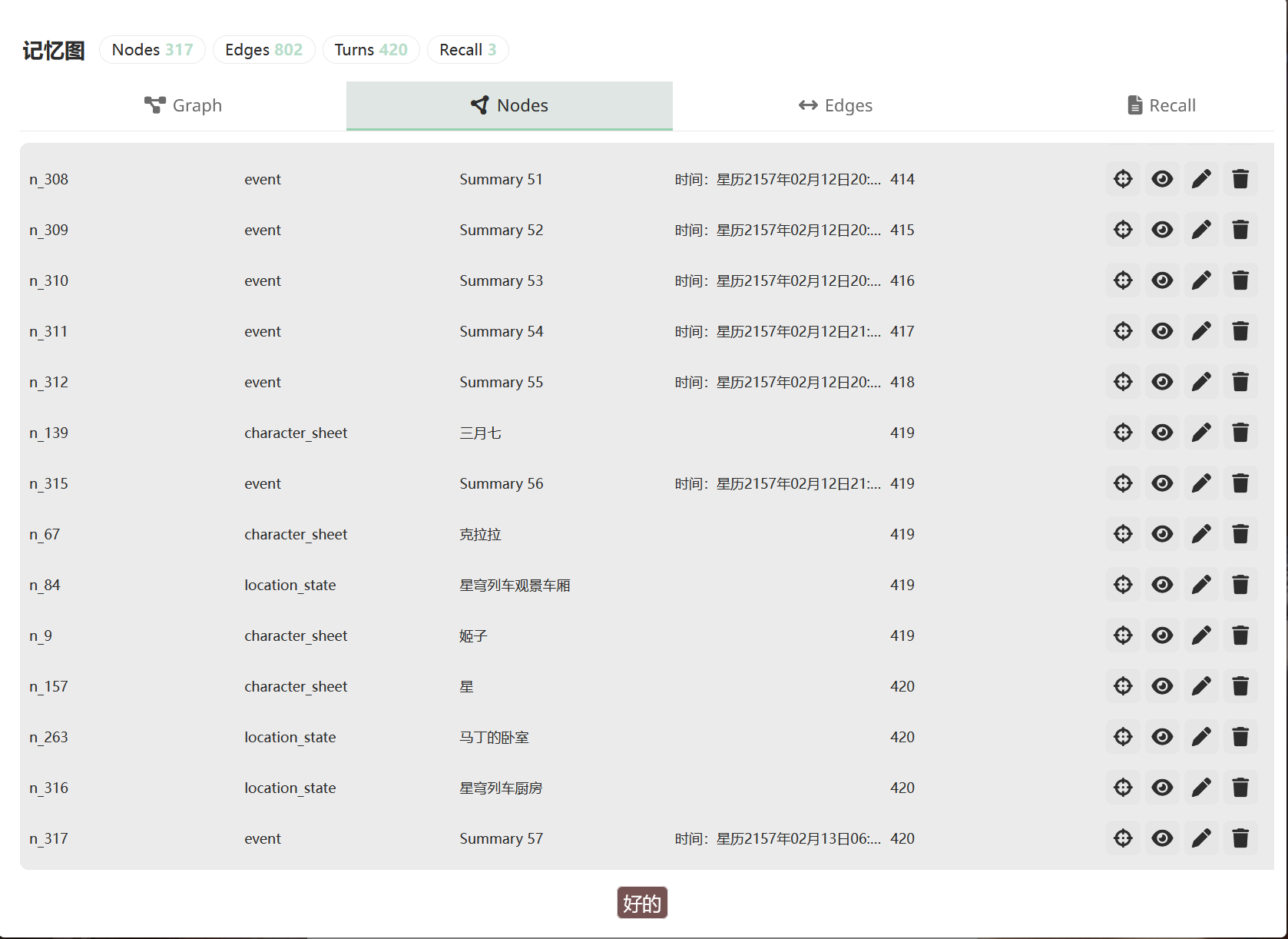
點任意節點看完整欄位:
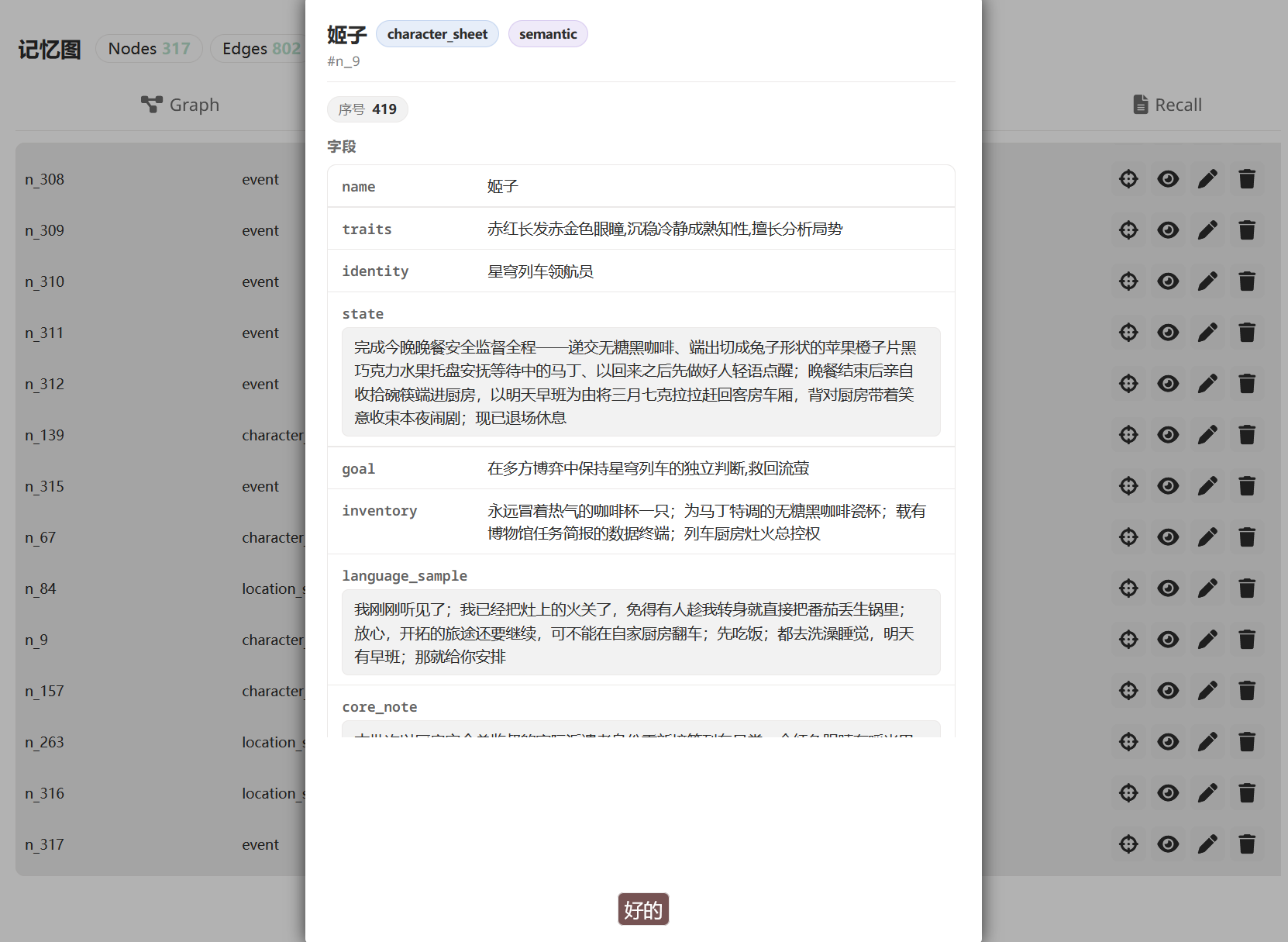
50 輪後,你說「對了 Eileen,你之前說欠我一個人情......」。記憶圖召回機制把這兩個節點(以及其他相關的)挑出來,在主模型生成回覆之前注入 prompt 的 SYSTEM 部分:
這就是記憶圖在做的事——它不讓 AI 忘掉那種「50 輪前的小事到 50 輪後突然變成關鍵」。
5 分鐘跑起來
Step 1 — 啟用
打開 擴展 抽屜 → 記憶 → 把 啟用 開關打開。
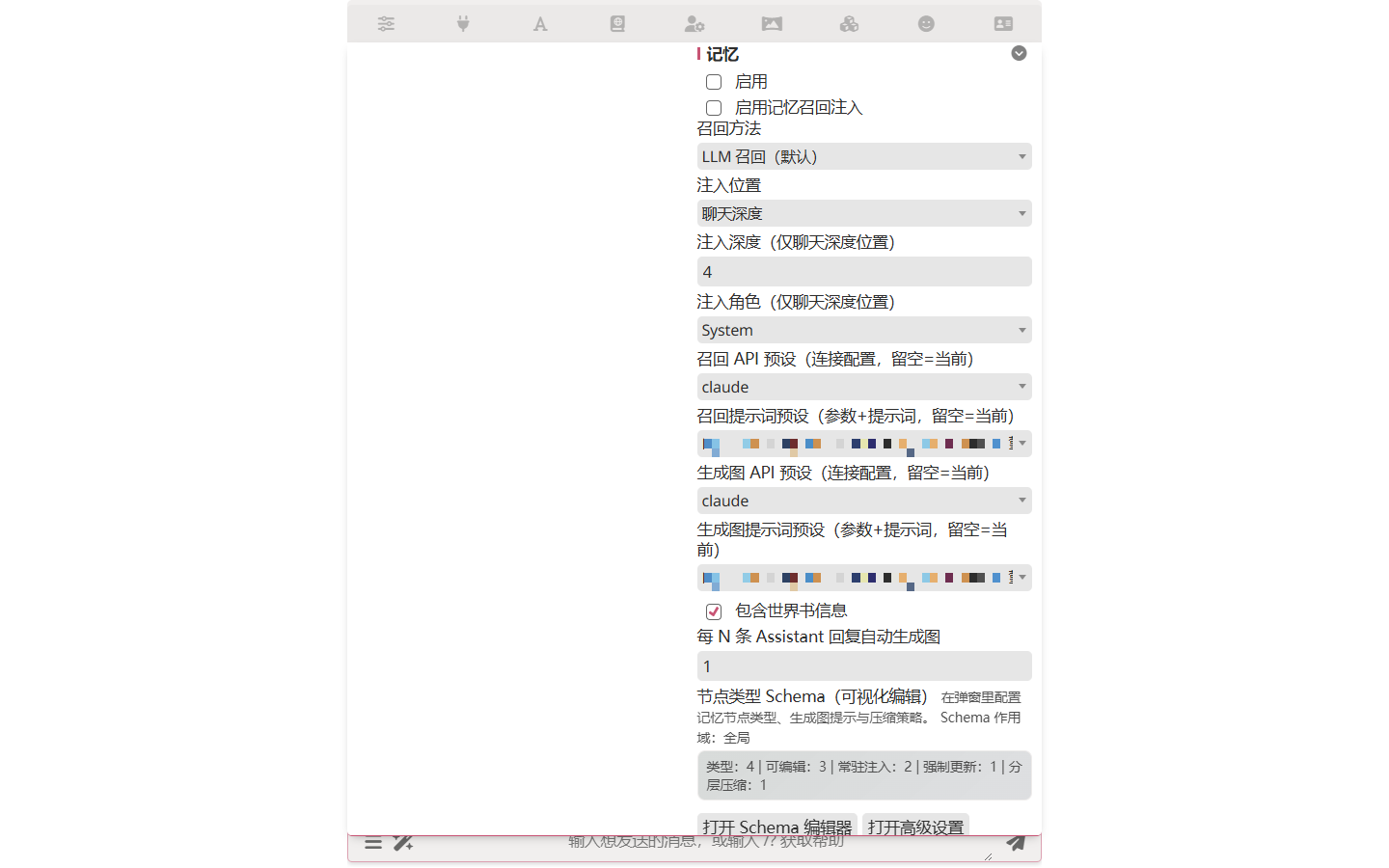
Step 2 — 給提取和召回選模型
記憶圖的提取和召回都要 LLM 呼叫,但不必和主對話用同一個模型。在同一面板設:
| 設定 | 說明 |
|---|---|
| 召回 API 預設 | 召回的 API 連接 |
| 召回提示詞預設 | 召回的 Chat Completion 預設 |
| 生成圖 API 預設 | 提取的 API 連接 |
| 生成圖提示詞預設 | 提取的 Chat Completion 預設 |
常見配法:主對話走 Claude Opus,記憶圖走 Haiku 或 Gemini Flash。提取做的是結構化欄位填充,不是寫文,小模型能處理,而且確實省錢。
Step 3 — 正常聊天
記憶圖自動運行。聊幾輪,內容裡包含一些值得記住的角色 / 事件 / 地點。
Step 4 — 看效果
3-5 輪後打開 Memory 面板:
- Graph 視圖——節點關係圖
- Nodes 表格——按類型展示節點結構化欄位
- Recall 視圖——最近一次注入到 prompt 裡的內容
如果什麼都沒看到,在聊天裡多帶幾個角色或事件——提取需要具體的東西可抓。
我想要……
常見問題,從「普遍」到「小眾」:
我想讓我的奇幻卡記住魔法體系 / 派系
記憶圖的節點類型可以自定義。在 Memory 面板點 打開 Schema 編輯器 加新類型:
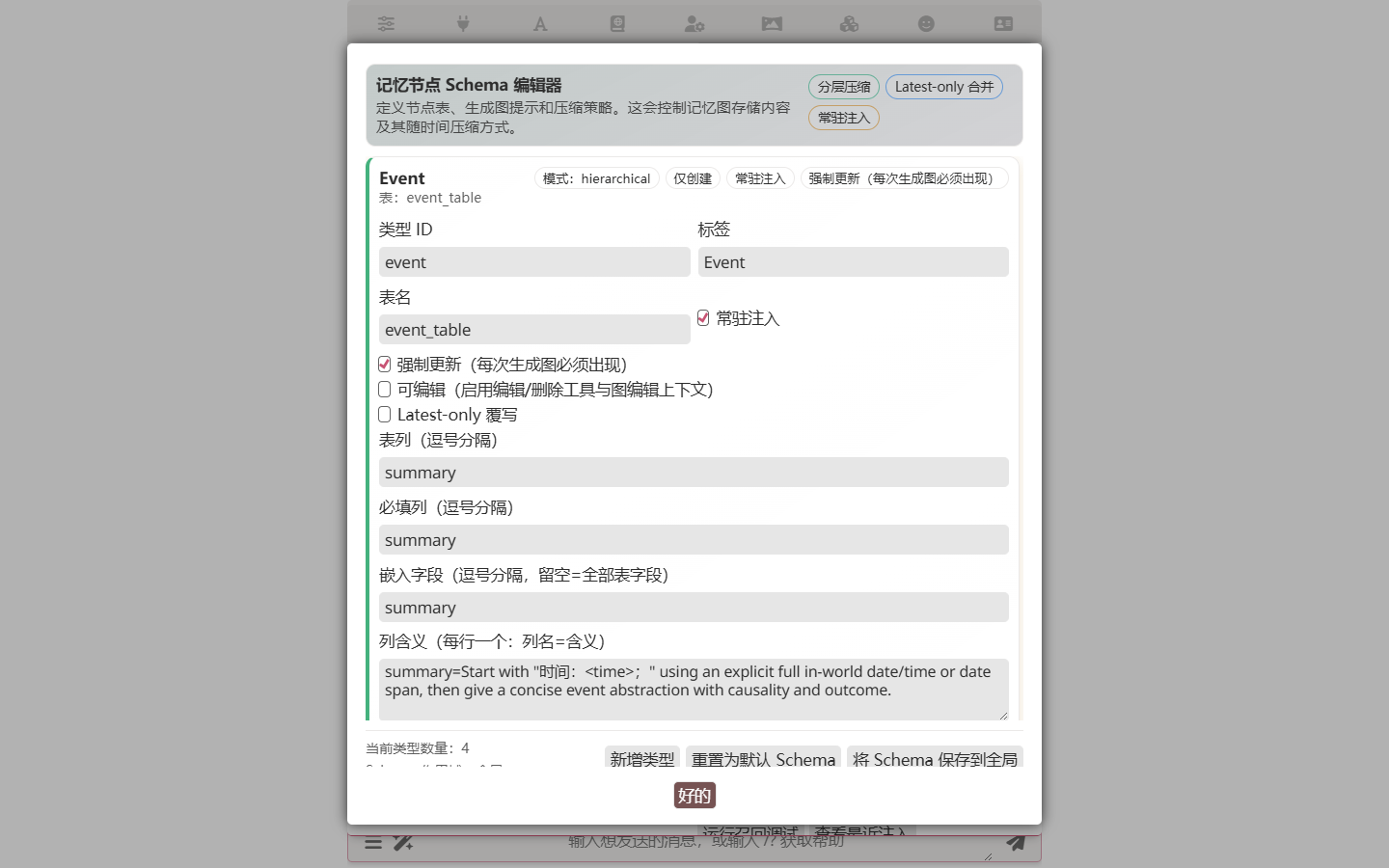
例如加一個 magic_system 類型(欄位:name / source / restrictions),或一個 faction 類型(欄位:name / leader / goals)。自定義類型保存在角色卡裡,匯出時隨卡走——你的奇幻世界詞彙隨卡傳遞。
每種類型還帶兩個提取控制欄位:
- 提取指令 —— 一段自由文本,僅當本類型本輪啟用時才會附加到提取系統提示詞。類型專屬規則(如「每批次最多一個 event」、「角色一定填 aliases」)寫在這裡,而不是塞進 base prompt。留空 = 無類型專屬附加段。
- 每 N 層提取一次 —— 節奏控制。
1(預設)表示每次提取都包含該類型。設為2/3/5等,僅當currentSeq % N == 0時啟用,適合location_state這種慢變化表,降低提取頻率、省 LLM 呼叫。某類型本輪未啟用時,其 create/edit/delete 工具不會暴露給模型,指令也不會附加 —— 模型這輪根本無法產出該表。
我想讓某些記憶 始終 在 prompt 裡(不等召回)
那是 持久注入。把某些節點類型設為持久注入——它們無論召回觸發與否都出現在 prompt 裡。常見用法:如果你加一個 rule_constraint 或 world_law 類型來表達不可違反的世界規則,把它標為持久——主模型就永遠不會忘掉這些規則。
持久注入和召回是互斥的(節點級)
持久注入的節點會從召回池裡完全排除——它已經每回合都在 prompt 裡了,運行時直接 bypass 掉它的召回。
我編輯 / 刪除訊息——記憶會怎麼變?
記憶圖有完整的變更回滾機制。你編輯、刪除訊息或 swipe 時,記憶自動回滾到受影響訊息之前的狀態,保持記憶和聊天歷史一致。
我想換電腦用 / 分享給別人
JSON 匯入匯出。
| 模式 | 作用 |
|---|---|
| Restore 還原 | 保留匯出時的樓層號——同一聊天恢復資料用 |
| 綁定到最新樓層 | 所有匯入節點綁到當前最新 AI 回覆樓層。 實用技巧:開一個全新的聊天,把過去某段長跑的記憶匯入進來,從 0 樓重新開始。等於「開新檔,但之前長跑裡累積的世界觀、角色、故事全在你腦子裡」——你可以續寫、換主線、換設定再玩一遍。 |
| 綁定到指定樓層 | 你手動輸入目標樓層 |
記憶怎麼進 prompt
兩條通道,節點級互斥。
持久注入——某些節點類型總在 prompt 裡。適合基線資訊:世界規則、人設核心設定、那種永遠不該忘的東西。在 Schema 編輯器裡按類型配置(alwaysInject 旗標)。持久節點會被從召回池裡排除——它每回合都在,不需要再被「召回」一遍。
召回注入——其他節點類型由召回機制動態注入,只有和當前對話相關的記憶才進 prompt,不浪費上下文空間。
底層實作:世界書投射
這兩條通道實際上都是把節點投射成世界書條目的方式工作的。持久注入寫持久世界書條目;召回注入寫臨時條目(生成完自動清理)。這意味著記憶條目會遵守世界書的關鍵詞掃描、深度排序等機制。這不是配置項,而是工作方式。
召回注入有自己的位置設定:
| 設定 | 預設 | 說明 |
|---|---|---|
| 召回注入位置 | atDepth | 注入位置 |
| 召回注入深度 | 9999 | 注入深度 |
| 召回注入角色 | SYSTEM | SYSTEM / USER / ASSISTANT |
結果複用
同一樓層 swipe 或重生成時,記憶圖會複用上次召回結果而不是重跑。省 LLM 成本,保證同一回合記憶上下文一致。
配置參考
完整配置列表
基礎配置
| 設定 | 預設 | 說明 |
|---|---|---|
| 啟用記憶圖 | false | 總開關 |
| 提取間隔 | 1 | 每 N 次 AI 回覆觸發一次提取 |
| 最大處理輪數 | 900 | 處理輪數硬上限 |
向量與重排
| 設定 | 預設 | 說明 |
|---|---|---|
| 嵌入檔案 | (空) | Connection Manager 裡的 embed-profile,記錄嵌入 Provider/模型/Endpoint/Key。可在記憶圖設定或向量儲存裡建立,多外掛共享。 |
| 向量 Top-K | 20 | 向量檢索 Top-K |
| 最大召回結果數 | 15 | 每輪注入到 prompt 的節點上限 |
| 啟用重排 | off | 是否在向量命中之上加一道交叉編碼重排 |
| 重排檔案 | (空) | Connection Manager 裡的 rerank-profile,定義重排 Provider/模型/Endpoint/Key。僅在「啟用重排」打開時被讀取,與向量儲存共享。 |
| 啟用查詢改寫 | off | 是否在檢索前加一次 LLM 呼叫,把最近對話改寫成一句更利於向量檢索的句子 |
| 查詢改寫 API 預設 | (空) | 改寫 LLM 呼叫使用的連線檔案,僅在「啟用查詢改寫」打開時被讀取 |
| 查詢改寫提示詞預設 | (空) | 改寫 LLM 呼叫使用的聊天補全預設 |
其他
| 設定 | 預設 | 說明 |
|---|---|---|
| RPM 限制 | 0 | 每分鐘請求數(0 = 不限) |
| LLM 可見最近訊息數 | 5 | 召回 LLM 能看到的最近訊息數 |
| 與預設一起包含世界書 | true | 用預設時是否包含世界書 |
| 覆寫世界書名稱 | (空) | 覆寫投射的世界書名 |
| 世界書條目排序基數 | 9800 | 投射條目的基礎排序值 |
| 工具呼叫最大重試 | 2 | 工具呼叫失敗重試次數 |
| 排除最近 N 輪的節點 | 0 | 召回時排除最近 N 輪的節點(0 = 不排除) |
技術深入
給好奇的讀者和貢獻者
RAG 召回管道
RAG 召回模式下,記憶圖跑一個三階段線性管道:
- 可選查詢改寫 —— 當「啟用查詢改寫」打開時,先用一次 LLM 呼叫把最近幾輪對話改寫成一句更適合向量檢索的句子(系統提示要求模型使用專有名詞和具體動詞,目標是產出和事件記錄原文用詞接近的檢索串)。
- 向量檢索 —— 用原始查詢或改寫後的句子去嵌入儲存裡取 Top-K 最相近節點。
- 可選交叉編碼重排 —— 當「啟用重排」打開時,把每個候選節點餵給重排模型重新打分,按重排分數重新排序。重排失敗時回退到向量分排序,不會讓整次召回失敗。
整個流程就這三步。沒有圖擴散階段,也沒有認知層——早期版本的記憶圖有一套 PEDSA 多階段擴散 + NMF/FISTA/DPP 認知層管道,但 A/B 實驗證明這些階段在真實長篇 RP 場景下對召回品質的貢獻為負或為零。最終決定把管道收斂為向量 + 可選重排 + 可選改寫,少給使用者設定錯的機會。
向量索引
記憶圖用增量更新策略管理向量嵌入——通過雜湊比對檢測節點內容變化,只有內容真的變了才重新生成嵌入向量。RAG 召回裡使用記憶圖設定中選定的嵌入檔案作為單一事實源,Provider/模型/Endpoint/Secret 全部從檔案讀取。向量儲存外掛從同一份 Connection-Manager 檔案庫讀取,兩個外掛可以共用一份檔案,也可以各自挑不同的檔案,不再依賴對方的私有 extension_settings。
插入向量時,記憶圖把 nodeId 放在 metadata 欄位裡。後端原樣存 metadata。其他外掛也可以用 metadata 欄位存自定義資料,查詢結果會一併返回。這種設計讓 hash → nodeId 映射可以繞開前端索引快取——即使快取丟了,也能從查詢結果直接匹配節點。
如需手動控制,記憶圖設定面板提供重算向量索引按鈕。點擊後彈出對話框,提供兩種模式:增量補全僅對向量缺失或失效(如節點編輯後)的節點重新生成 embedding;全部重算清空集合並對所有可索引節點重新生成 embedding(更換嵌入模型或檔案後用此項)。如果嵌入設定已變更,增量補全會自動升級為全部重算,因為舊向量與新空間不相容。失敗的節點記錄到主控台,不阻斷整體流程。
自動 schema 遷移
載入聊天時,記憶圖運行遷移管道,把舊的持久化形態(v5 raw,v8 opLog)轉換為當前的 v2 樓層狀態佈局(graph payload + __floor_log 提交日誌 + __meta 狀態)。管道冪等,只在輸入形態不是 v2 時運行,任何步驟失敗時絕不修改 chat-state。
更多實作細節請看原始碼。
相關頁面
- Function Call Runtime — 記憶圖的 LLM 互動依賴此框架
- 世界書基礎 — 世界書投射涉及的基礎概念