记忆图
记忆图(Memory Graph)解决长跑 RP 里最常见的一个痛点:角色失忆。
LLM 的上下文窗口是有限的。聊到几百轮以后,早期的重要信息——人物关系、关键事件、世界规则——会被截断丢掉。角色就「忘了」之前发生的事。记忆图把对话里的关键信息自动抽成结构化的知识节点,需要时再召回注入回 prompt——让角色能像你一样,记住 500 轮前发生的事情。
它不是简单的关键词搜索或纯向量检索。记忆图用图结构和多层算法,让召回既语义相关又覆盖全面——不会出现「只把最相似的五条拉出来,其他都丢了」的情况。
它怎么工作
记忆图后台跑三件事:自动提取、智能召回、分层压缩。
自动提取
每次 AI 回复后,记忆图分析对话内容,把值得记住的东西提取出来,产出结构化的知识节点。提取可以走两条通道:
内置提取 —— 当记忆面板里的 自动抽取 开关打开时,记忆图在每次 AI 回复后自己跑一次 LLM 调用,把 schema 里的结构化字段填出来。这是默认方式,不依赖任何其他扩展。
编排器驱动的提取 —— 当编排器扩展已安装,且导演模式使用默认配置时,主 agent 在每次起草回复后会调度一个 memory_curator 子 agent。memory_curator 跑多轮"观察—执行"循环,先用记忆图的只读工具确认现状,再写入。对像角色这类稳定事实节点,质量通常更高 —— agent 会先查是否已有同名角色,而不是直接新建出重复节点。
两条通道可以同时开,它们彼此并不协调,等于用额外的 LLM 成本换取一层兜底。多数用户只会留一条。
只走编排器驱动的提取:
- 打开记忆面板,把 自动抽取 关掉。
- 在编排器配置编辑器里确认
memory_curator已启用,并且由主 agent 调度(新装默认就是这样)。
节点分两层。默认 schema 自带下面这三种类型,但 schema 是完全可定制的。你可以新增节点类型(奇幻题材加 magic_system,政治题材加 faction,生存题材加 inventory_item,看你的卡需要什么),也可以移除任何默认类型。下面字段也是默认值,每种类型的字段可以在 Schema 编辑器里改(下面会讲到)。
语义层节点(持久化结构化知识,合并和更新):
| 类型 | 说明 | 例子 |
|---|---|---|
character_sheet | 角色的姓名、身份、性格、目标、随身物品 | 「Eileen 是治愈师,认下了对主角的一份恩情」 |
location_state | 地点的名称、控制者、危险度、资源 | 「黑暗森林由精灵控制,危险度高」 |
事件层节点(情节记录,每次提取新建,从不合并):
| 类型 | 说明 | 例子 |
|---|---|---|
event | 发生过的重要事件 | 「主角在森林中遭遇伏击」 |
事件节点不一样
事件节点和其他类型有本质区别:
- 每次提取都新建节点。 标题自动递增。事件是时间轴上独立的点,不像角色状态那样合并到现有节点
- 最高层时间线总是注入。 事件节点是核心剧情上下文——最高层级的总结永远在 prompt 里,确保 AI 始终把握剧情走向
- 被压缩的低层事件隐藏。 事件累积太多时,旧事件向上压缩成更高层的总结。低层事件依然在图里,需要时召回机制能再发现它们,但默认不持久注入
简单说:AI 始终能看到「大事」(最高层总结),具体细节只在对话需要时召回补充。
可以通过 提取间隔 控制提取频率——比如设为 2 表示每 2 次 AI 回复才触发一次提取,LLM 调用成本减半。
智能召回
你发新消息触发 AI 生成时,记忆图根据当前对话上下文,从累积的记忆中召回最相关的节点,注入 prompt 供 AI 参考。
| 召回方式 | 说明 |
|---|---|
| LLM 召回 | 让 LLM 直接从记忆库里挑相关节点,支持多轮深度探索 |
| RAG 召回 | 对嵌入的记忆库做向量检索,可选叠加交叉编码重排和 LLM 查询改写 |
选哪个?
LLM 召回是默认的,因为最容易配 —— 你的主对话已经有 LLM API,这就够用了。
RAG 召回更快、更贴近生产级检索系统的玩法(语义向量检索)。需要先配好嵌入档案(embedding profile):档案存在 Connection Manager 的嵌入面板里,和聊天补全连接并列,多个插件(Vector Storage、记忆图、未来的扩展)可以共用同一份 provider/模型/key 三元组。
RAG 召回里有两个独立的开关,可以用额外成本换更好的效果:
- 启用重排 —— 在向量命中之上加一道交叉编码重排。当嵌入模型偏小、重排模型偏强时收益最明显;需要配一份重排档案(cohere / jina / 自定义端点)。
- 启用查询改写 —— 在检索前加一次 LLM 调用,把最近几轮对话改写成一句更适合向量检索的简洁句子。当用户的提问比较泛、或者绕弯子时,召回质量提升明显。代价是每轮多一次 LLM 调用(延迟+成本)。
经验法则:刚上手就 LLM 召回;碰到成本或延迟瓶颈、或者想让召回结果在换模型后保持稳定时,切到 RAG 召回。两个开关相互独立,可以分别打开试用。
分层压缩
随着对话推进,事件记忆持续累积。记忆图自动对老事件做向上压缩——多个相关事件合并为更高层的总结节点,既保留核心信息又控制总记忆体积。
压缩是递归的。某层的总结节点也超阈值时,继续向上压缩,直到节点数降到阈值以下。例如多个战斗事件先压成「森林战役」,多场战役再压成「北征之战」。压缩后的总结节点仍可展开看原始子事件。
和提取类似,压缩也有两条通道:
内置压缩 —— 当记忆面板里的 自动压缩 开关打开时,叶子层事件累积到阈值后,记忆图跑一次性的 LLM 总结调用。
编排器驱动的压缩 —— memory_curator 在提取之后会评估 memory_compaction_candidates,然后用 KEEP/FOLD/DROP 风格的总结调 memory_compact_nodes。多轮 agent 可以一个 rollup 一个 rollup 反复迭代,而内置路径是一次性的。
它实际长什么样
读到这儿大多数读者都想知道一个具体问题:节点到底长什么样?来个真实例子。
假设你和 Eileen(一个治愈师 NPC)有这样三轮对话:
You: 我把找到的伤药递给 Eileen。
Eileen: ...谢谢。但你确定要给我?这种东西在外面很值钱。
You: 你伤得比我重。再说,我们是朋友吧。
Eileen: ...嗯。是朋友。这个恩情我会记着的。
这一轮后,记忆图在后台跑一次提取,产生这样的结构化节点:
{
"id": "n_eileen",
"type": "character_sheet",
"level": "semantic",
"title": "Eileen",
"fields": {
"aliases": "",
"traits": "话不多,字斟句酌,即使道谢也很克制",
"identity": "在北境遇到的旅行治愈师",
"goal": "还这份恩情;伤好到能自己走路",
"inventory": "伤药(刚收下)、轻便行囊",
"language_sample": "...谢谢。但你确定要给我?",
"addressing_user": "称呼用名字,中间常有停顿"
},
"floor": 12
}{
"id": "evt_20260505_001",
"type": "event",
"level": "semantic",
"title": "Summary 1",
"fields": {
"summary": "时间: 第 12 天傍晚\n地点: 北境驿道旁的临时营地\n\n用户把背包里仅剩的伤药递给受伤的 Eileen, Eileen 短暂迟疑后接下, 并以平稳的语气明确认下了这份恩情和二人之间的朋友关系。\n\n不可逆:\n- 用户与 Eileen 建立朋友关系\n- Eileen 欠用户一份明确承认的恩情"
},
"floor": 12
}这就是默认 schema 的字段
上面例子里的字段(character_sheet 用的 aliases / traits / identity / goal / inventory / language_sample / addressing_user,event 用的 summary)就是默认表的真实列。Schema 编辑器里可以改名、删除,或者干脆加新类型。
记忆图的面板里你能看到所有节点,可以是图,也可以是表格:
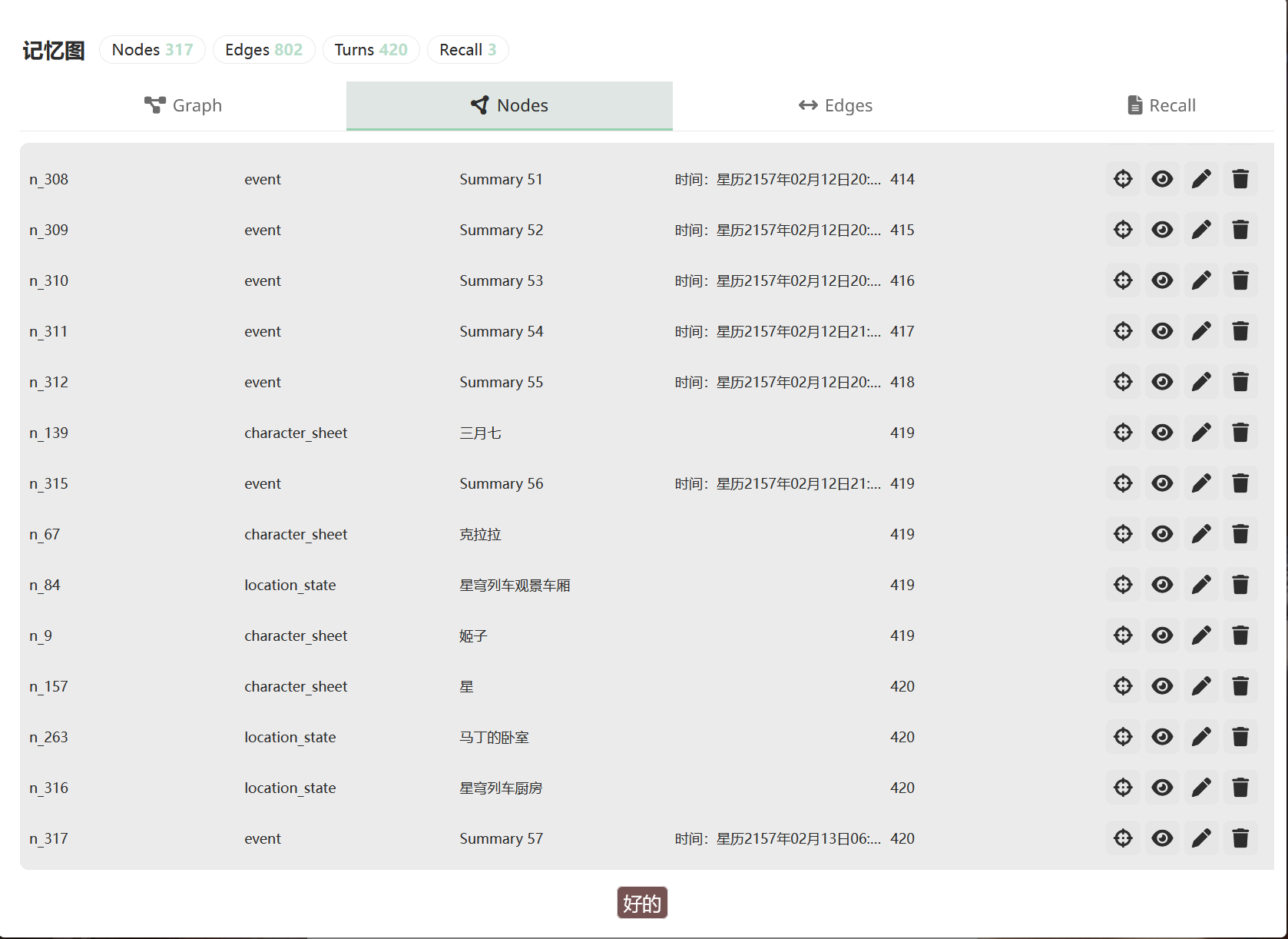
点任意节点看完整字段:
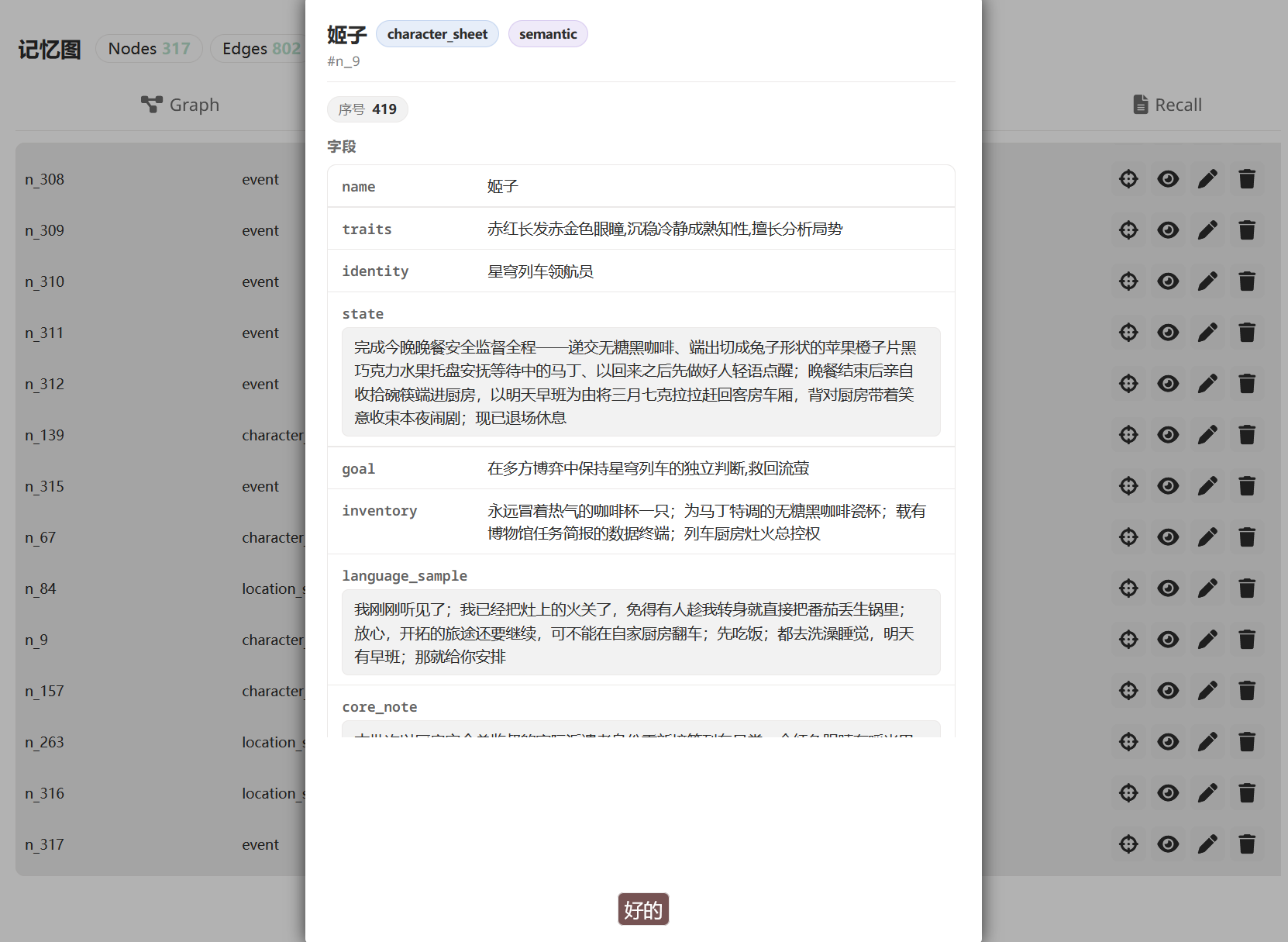
50 轮后,你说「对了 Eileen,你之前说欠我一个人情......」。记忆图召回机制把这两个节点(以及其他相关的)挑出来,在主模型生成回复之前注入 prompt 的 SYSTEM 部分:
这就是记忆图在做的事——它不让 AI 忘掉那种「50 轮前的小事到 50 轮后突然变成关键」。
5 分钟跑起来
Step 1 — 启用
打开 扩展 抽屉 → 记忆 → 把 启用 开关打开。
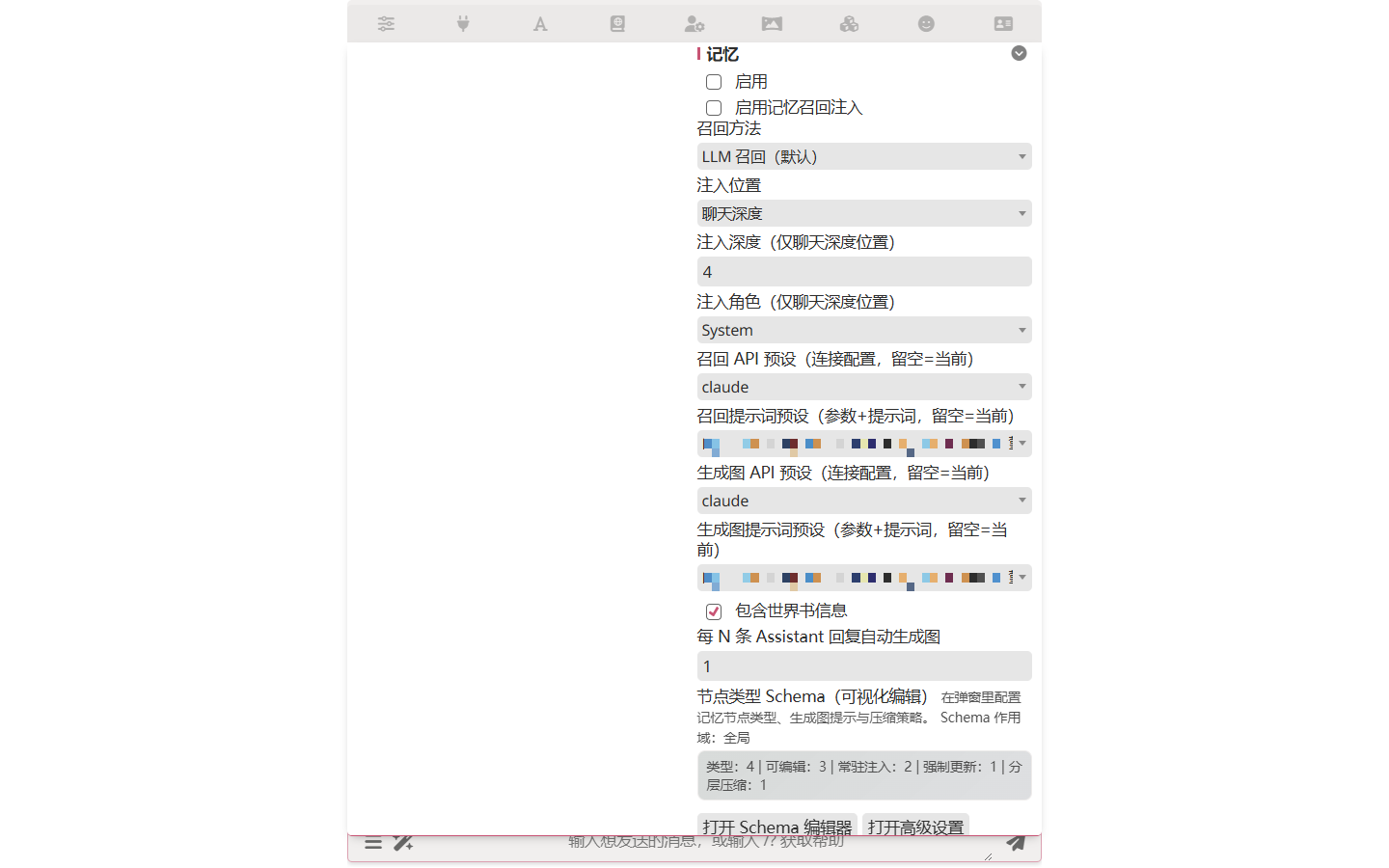
Step 2 — 给提取和召回选模型
记忆图的提取和召回都要 LLM 调用,但不必和主对话用同一个模型。在同一面板设:
| 设置 | 说明 |
|---|---|
| 召回 API 预设 | 召回的 API 连接 |
| 召回提示词预设 | 召回的 Chat Completion 预设 |
| 生成图 API 预设 | 提取的 API 连接 |
| 生成图提示词预设 | 提取的 Chat Completion 预设 |
常见配法:主对话走 Claude Opus,记忆图走 Haiku 或 Gemini Flash。提取做的是结构化字段填充,不是写文,小模型能处理,而且确实省钱。
Step 3 — 正常聊天
记忆图自动运行。聊几轮,内容里包含一些值得记住的角色 / 事件 / 地点。
Step 4 — 看效果
3-5 轮后打开 Memory 面板:
- Graph 视图——节点关系图
- Nodes 表格——按类型展示节点结构化字段
- Recall 视图——最近一次注入到 prompt 里的内容
如果什么都没看到,在聊天里多带几个角色或事件——提取需要具体的东西可抓。
我想要……
常见问题,从「普遍」到「小众」:
我想让我的奇幻卡记住魔法体系 / 派系
记忆图的节点类型可以自定义。在 Memory 面板点 打开 Schema 编辑器 加新类型:
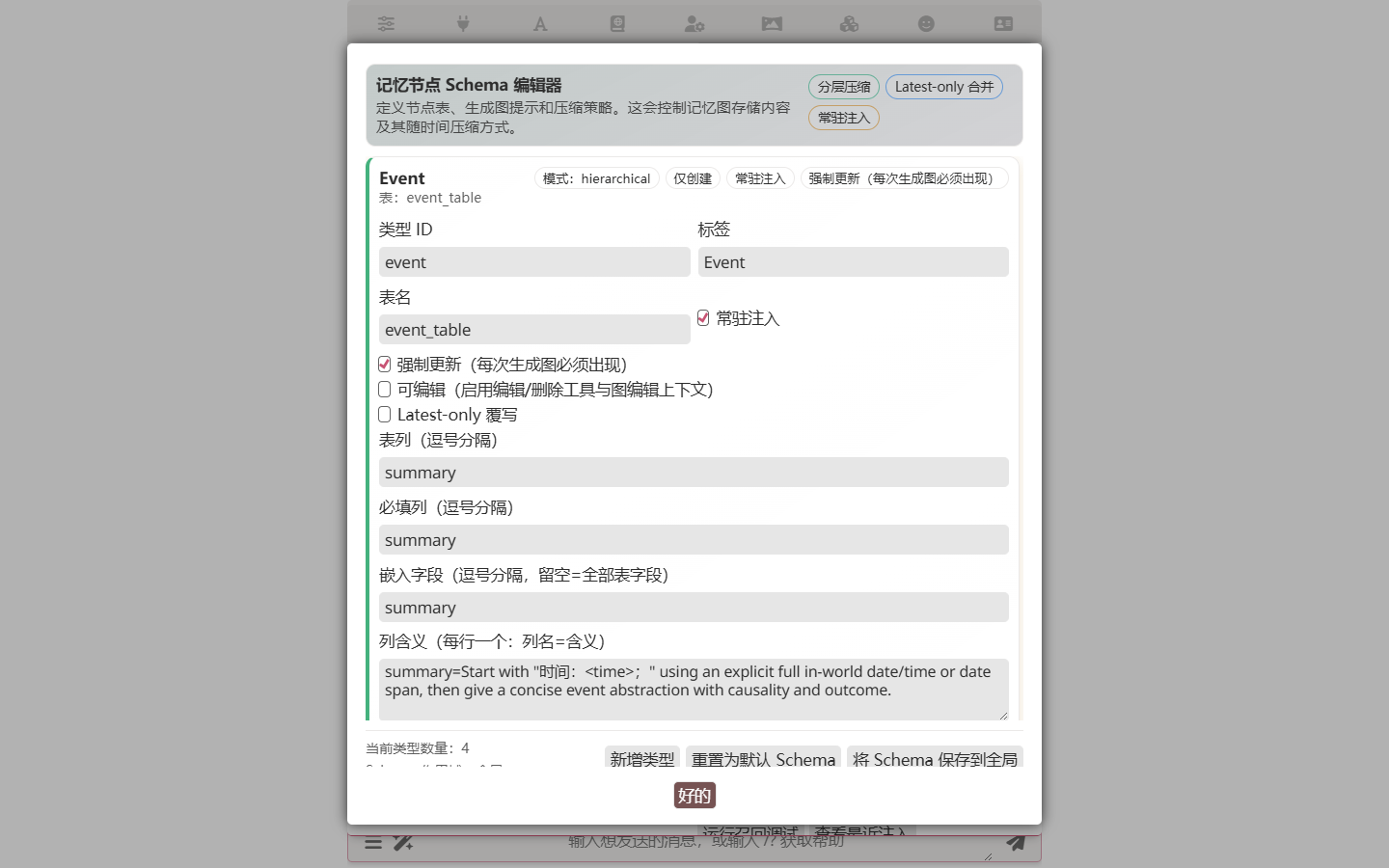
例如加一个 magic_system 类型(字段:name / source / restrictions),或一个 faction 类型(字段:name / leader / goals)。自定义类型保存在角色卡里,导出时随卡走——你的奇幻世界词汇随卡传递。
每种类型还带两个提取控制字段:
- 提取指令 —— 一段自由文本,仅当本类型本轮启用时才会附加到提取系统提示词。类型专属规则(如"每批次最多一个 event"、"角色一定填 aliases")写在这里,而不是塞进 base prompt。留空 = 无类型专属附加段。
- 每 N 层提取一次 —— 节奏控制。
1(默认)表示每次提取都包含该类型。设为2/3/5等,仅当currentSeq % N == 0时启用,适合location_state这种慢变化表,降低提取频率、省 LLM 调用。某类型本轮未启用时,其 create/edit/delete 工具不会暴露给模型,指令也不会附加 —— 模型这轮根本无法产出该表。
我想让某些记忆 始终 在 prompt 里(不等召回)
那是 持久注入。把某些节点类型设为持久注入——它们无论召回触发与否都出现在 prompt 里。常见用法:如果你加一个 rule_constraint 或 world_law 类型来表达不可违反的世界规则,把它标为持久——主模型就永远不会忘掉这些规则。
持久注入和召回是互斥的(节点级)
持久注入的节点会从召回池里完全排除——它已经每回合都在 prompt 里了,运行时直接 bypass 掉它的召回。
我编辑 / 删除消息——记忆会怎么变?
记忆图有完整的变更回滚机制。你编辑、删除消息或 swipe 时,记忆自动回滚到受影响消息之前的状态,保持记忆和聊天历史一致。
我想换电脑用 / 分享给别人
JSON 导入导出。
| 模式 | 作用 |
|---|---|
| Restore 还原 | 保留导出时的楼层号——同一聊天恢复数据用 |
| 绑定到最新楼层 | 所有导入节点绑到当前最新 AI 回复楼层。 实用技巧:开一个全新的聊天,把过去某段长跑的记忆导进来,从 0 楼重新开始。等于「开新档,但之前长跑里积累的世界观、角色、故事全在你脑子里」——你可以续写、换主线、换设定再玩一遍。 |
| 绑定到指定楼层 | 你手动输入目标楼层 |
记忆怎么进 prompt
两条通道,节点级互斥。
持久注入——某些节点类型总在 prompt 里。适合基线信息:世界规则、人设核心设定、那种永远不该忘的东西。在 Schema 编辑器里按类型配置(alwaysInject 标志)。持久节点会被从召回池里排除——它每回合都在,不需要再被「召回」一遍。
召回注入——其他节点类型由召回机制动态注入,只有和当前对话相关的记忆才进 prompt,不浪费上下文空间。
底层实现:世界书投射
这两条通道实际上都是把节点投射成世界书条目的方式工作的。持久注入写持久世界书条目;召回注入写临时条目(生成完自动清理)。这意味着记忆条目会遵守世界书的关键词扫描、深度排序等机制。这不是配置项,而是工作方式。
召回注入有自己的位置设置:
| 设置 | 默认 | 说明 |
|---|---|---|
| 召回注入位置 | atDepth | 注入位置 |
| 召回注入深度 | 9999 | 注入深度 |
| 召回注入角色 | SYSTEM | SYSTEM / USER / ASSISTANT |
结果复用
同一楼层 swipe 或重生成时,记忆图会复用上次召回结果而不是重跑。省 LLM 成本,保证同一回合记忆上下文一致。
配置参考
完整配置列表
基础配置
| 设置 | 默认 | 说明 |
|---|---|---|
| 启用记忆图 | false | 总开关 |
| 提取间隔 | 1 | 每 N 次 AI 回复触发一次提取 |
| 最大处理轮数 | 900 | 处理轮数硬上限 |
向量与重排
| 设置 | 默认 | 说明 |
|---|---|---|
| 嵌入档案 | (空) | Connection Manager 里的 embed-profile,记录嵌入 Provider/模型/Endpoint/Key。可在记忆图设置或向量存储里创建,多插件共享。 |
| 向量 Top-K | 20 | 向量检索 Top-K |
| 最大召回结果数 | 15 | 每轮注入到 prompt 的节点上限 |
| 启用重排 | off | 是否在向量命中之上加一道交叉编码重排 |
| 重排档案 | (空) | Connection Manager 里的 rerank-profile,定义重排 Provider/模型/Endpoint/Key。仅在"启用重排"打开时被读取,与向量存储共享。 |
| 启用查询改写 | off | 是否在检索前加一次 LLM 调用,把最近对话改写成一句更利于向量检索的句子 |
| 查询改写 API 预设 | (空) | 改写 LLM 调用使用的连接档案,仅在"启用查询改写"打开时被读取 |
| 查询改写提示词预设 | (空) | 改写 LLM 调用使用的聊天补全预设 |
其他
| 设置 | 默认 | 说明 |
|---|---|---|
| RPM 限制 | 0 | 每分钟请求数(0 = 不限) |
| LLM 可见最近消息数 | 5 | 召回 LLM 能看到的最近消息数 |
| 与预设一起包含世界书 | true | 用预设时是否包含世界书 |
| 覆写世界书名称 | (空) | 覆写投射的世界书名 |
| 世界书条目排序基数 | 9800 | 投射条目的基础排序值 |
| 工具调用最大重试 | 2 | 工具调用失败重试次数 |
| 排除最近 N 轮的节点 | 0 | 召回时排除最近 N 轮的节点(0 = 不排除) |
技术深入
给好奇的读者和贡献者
RAG 召回管道
RAG 召回模式下,记忆图跑一个三阶段线性管道:
- 可选查询改写 —— 当"启用查询改写"打开时,先用一次 LLM 调用把最近几轮对话改写成一句更适合向量检索的句子(系统提示要求模型使用专有名词和具体动词,目标是产出和事件记录原文用词接近的检索串)。
- 向量检索 —— 用原始查询或改写后的句子去嵌入存储里取 Top-K 最相近节点。
- 可选交叉编码重排 —— 当"启用重排"打开时,把每个候选节点喂给重排模型重新打分,按重排分数重新排序。重排失败时回退到向量分排序,不会让整次召回失败。
整个流程就这三步。没有图扩散阶段,也没有认知层——早期版本的记忆图有一套 PEDSA 多阶段扩散 + NMF/FISTA/DPP 认知层管道,但 A/B 实验证明这些阶段在真实长篇 RP 场景下对召回质量的贡献为负或为零。最终决定把管道收敛为向量 + 可选重排 + 可选改写,少给用户配错的机会。
向量索引
记忆图用增量更新策略管理向量嵌入——通过哈希比对检测节点内容变化,只有内容真的变了才重新生成嵌入向量。RAG 召回里使用记忆图设置中选定的嵌入档案作为单一事实源,Provider/模型/Endpoint/Secret 全部从档案读取。向量存储插件从同一份 Connection-Manager 档案库读取,两个插件可以共用一份档案,也可以各自挑不同的档案,不再依赖对方的私有 extension_settings。
插入向量时,记忆图把 nodeId 放在 metadata 字段里。后端原样存 metadata。其他插件也可以用 metadata 字段存自定义数据,查询结果会一并返回。这种设计让 hash → nodeId 映射可以绕开前端索引缓存——即使缓存丢了,也能从查询结果直接匹配节点。
如需手动控制,记忆图设置面板提供重算向量索引按钮。点击后弹出对话框,提供两种模式:增量补全仅对向量缺失或失效(如节点编辑后)的节点重新生成 embedding;全部重算清空集合并对所有可索引节点重新生成 embedding(更换嵌入模型或档案后用此项)。如果嵌入配置已变更,增量补全会自动升级为全部重算,因为旧向量与新空间不兼容。失败的节点记录到控制台,不阻断整体流程。
自动 schema 迁移
加载聊天时,记忆图运行迁移管道,把旧的持久化形态(v5 raw,v8 opLog)转换为当前的 v2 楼层状态布局(graph payload + __floor_log 提交日志 + __meta 状态)。管道幂等,只在输入形态不是 v2 时运行,任何步骤失败时绝不修改 chat-state。
更多实现细节请看源码。
相关页面
- Function Call Runtime — 记忆图的 LLM 交互依赖此框架
- 世界书基础 — 世界书投射涉及的基础概念